背景介绍:
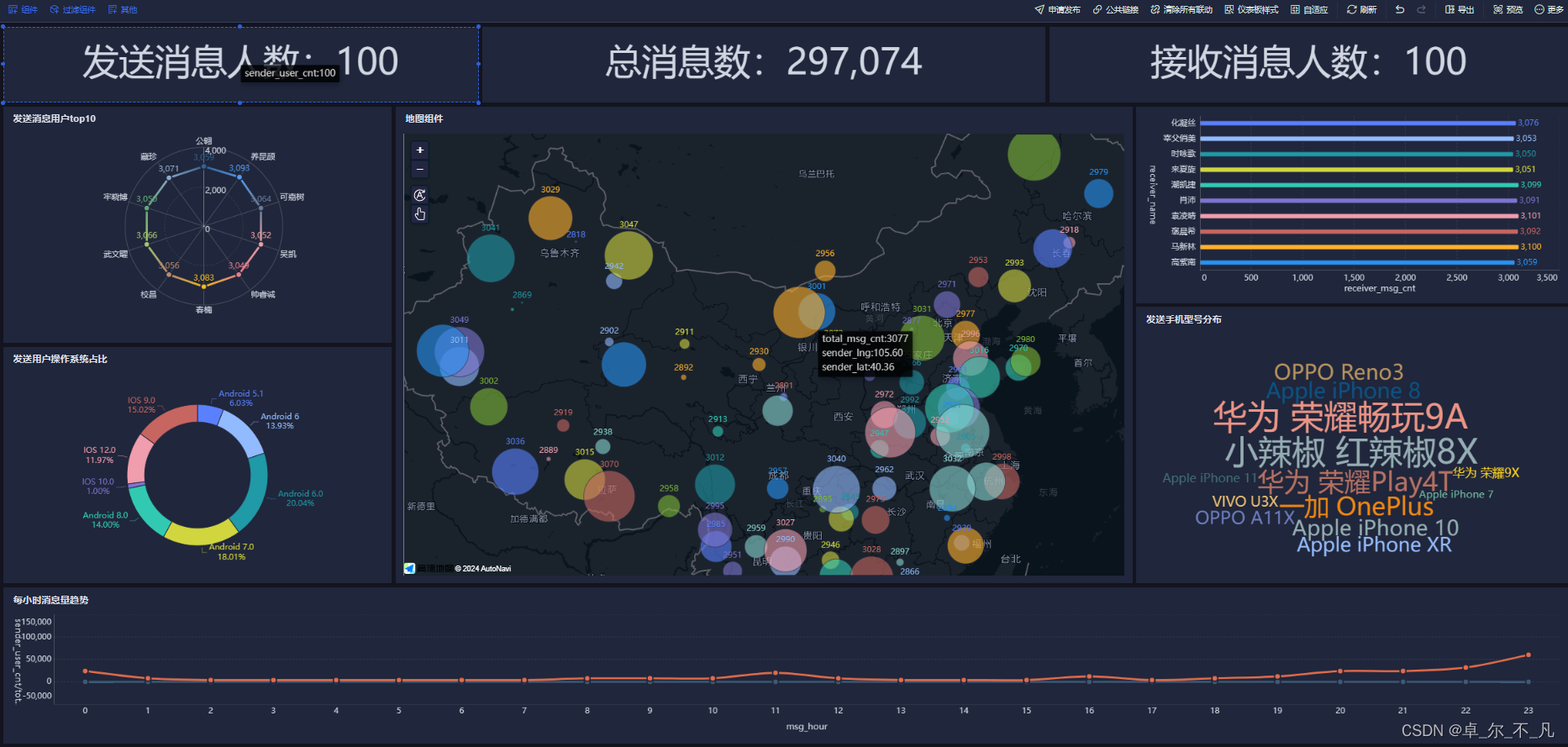
聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。 我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。
目标:
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表
需求分析:
统计今日总消息量 统计今日每小时消息量、发送和接收用户数
统计今日各地区发送消息数据量
统计今日发送消息和接收消息的用户数
统计今日发送消息最多的Top10用户
统计今日接收消息最多的Top10用户
统计发送人的手机型号分布情况
统计发送人的设备操作系统分布情况
数据源:数据源
数据大小:30万条数据
列分隔符:Hive默认分隔符’\001’
数据字典及样例数据

构建数据库数据表hive:
create database db_msg;
use db_msg;
--建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
);将数据源上传到Linux文件系统中,再上传到hadoop中:
[hadoop@node1 ~]$ hadoop fs -mkdir -p /chatdemo/data
[hadoop@node1 ~]$ hadoop fs -put chat_data-30W.csv /chatdemo/data将数据源从hadoop中下载到hive数据库中:
load data inpath '/chatdemo/data/chat_data-30W.csv' into table db_msg.tb_msg_source; 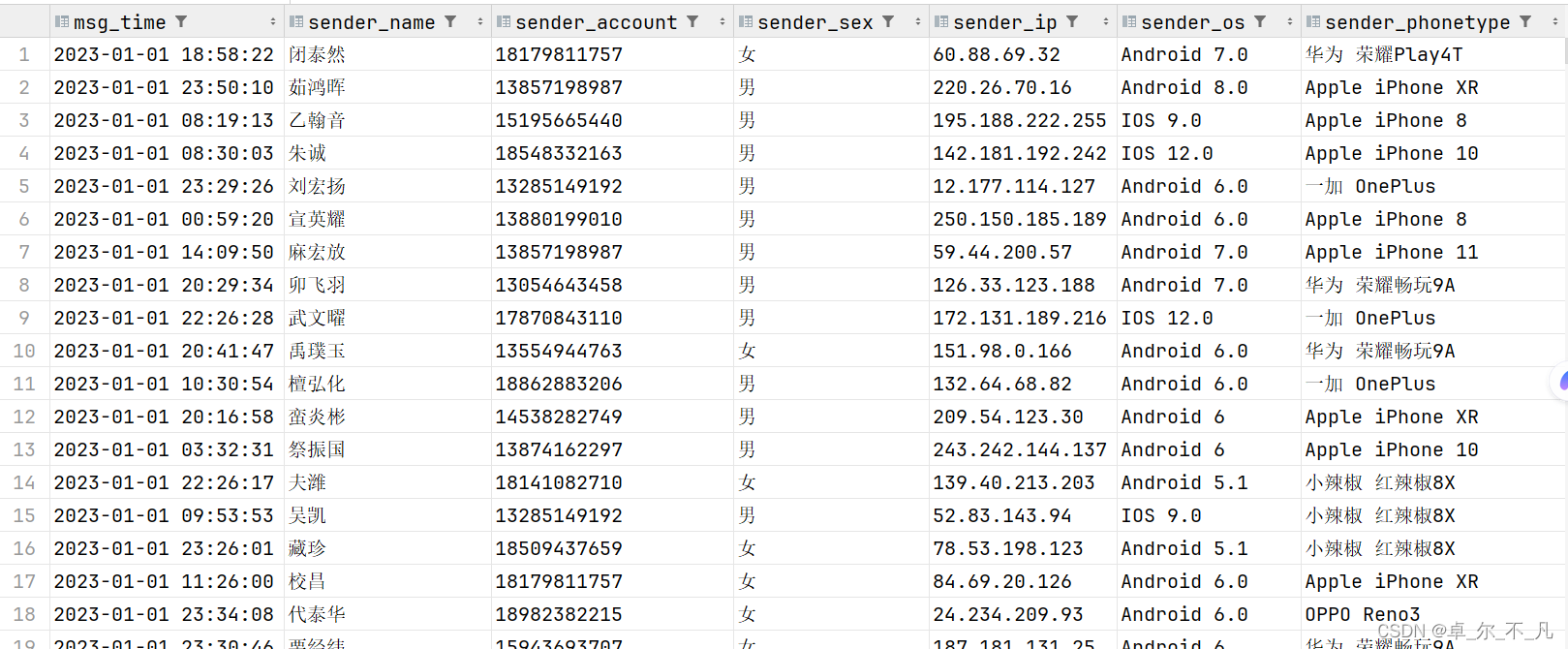
数据清洗:
问题1:当前数据中,有一些数据的字段为空,不是合法数据
问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理

数据清洗:
select*,date(msg_time) as msg_day,hour(msg_time) as msg_hour,split(sender_gps,',')[0] as sender_lng,split(sender_gps,',')[1] as sender_lat
from tb_msg_source
where length(sender_gps)>0;将清洗后的数据在放入新表中,添加新的字段:
create table db_msg.tb_msg_etl(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容",
msg_day string comment "消息日",
msg_hour string comment "消息小时",
sender_lng double comment "经度",
sender_lat double comment "纬度"
);
将数据插入到新表:
insert overwrite table db_msg.tb_msg_etl
select*,date(msg_time) as msg_day,hour(msg_time) as msg_hour,split(sender_gps,',')[0] as sender_lng,split(sender_gps,',')[1] as sender_lat
from tb_msg_source
where length(sender_gps)>0;将需求指标查询出来构建新表:
-- 统计今日总消息量
create table db_msg.tb_rs_total_msg_cnt comment '每日消息总量' as
select msg_day, count(*) as total_msg_cnt from db_msg.tb_msg_etl group by msg_day ;
-- 统计今日每小时消息量、发送和接收用户数
create table db_msg.tb_rs_hour_msg_cnt comment '每小时消息量趋势' as
selectmsg_hour,count(*) as total_msg_cnt,count(distinct sender_account) as sender_user_cnt,count(distinct receiver_account) as receiver_user_cnt
from db_msg.tb_msg_etl
group by msg_hour;
-- 统计今日各地区发送消息数据量
create table db_msg.tb_rs_loc_cnt comment '每日各地区发送消息总量' as
selectmsg_day,sender_lng,sender_lat,count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by msg_day,sender_lng,sender_lat
-- 统计今日发送消息和接收消息的用户数
create table db_msg.tb_rs_user_cnt comment '每日发送和接收消息的人数' as
selectmsg_day,count(distinct sender_account) as sender_user_cnt,count(distinct receiver_account) as receiver_user_cnt
from db_msg.tb_msg_etl
group by msg_day;
-- 统计今日发送消息最多的Top10用户
create table db_msg.tb_rs_s_user_top10 comment '发送消息最多的10个用户' as
selectsender_name,count(*) as sender_msg_cnt
from db_msg.tb_msg_etl group by sender_name
order by sender_msg_cnt desc
limit 10;
-- 统计今日接收消息最多的Top10用户
create table db_msg.tb_rs_r_user_top10 comment '接受消息最多的10个用户' as
selectreceiver_name,count(*) as receiver_msg_cnt
from db_msg.tb_msg_etl group by tb_msg_etl.receiver_name
order by receiver_msg_cnt desc
limit 10;
-- 统计发送人的手机型号分布情况
create table db_msg.tb_rs_sender_phone comment '发送人的手机型号分布' as
selectsender_phonetype,count(*) as cnt
from db_msg.tb_msg_etl group by sender_phonetype;
-- 统计发送人的设备操作系统分布情况
create table db_msg.tb_rs_sender_os comment '发送人的os分布' as
selectsender_os,count(*) as cnt
from db_msg.tb_msg_etl group by sender_os; 
基于FineBI完成指标的可视化展示: